Categories &
Functions List
- BetaDistribution
- BinomialDistribution
- BirnbaumSaundersDistribution
- BurrDistribution
- ExponentialDistribution
- ExtremeValueDistribution
- GammaDistribution
- GeneralizedExtremeValueDistribution
- GeneralizedParetoDistribution
- HalfNormalDistribution
- InverseGaussianDistribution
- LogisticDistribution
- LoglogisticDistribution
- LognormalDistribution
- LoguniformDistribution
- MultinomialDistribution
- NakagamiDistribution
- NegativeBinomialDistribution
- NormalDistribution
- PiecewiseLinearDistribution
- PoissonDistribution
- RayleighDistribution
- RicianDistribution
- tLocationScaleDistribution
- TriangularDistribution
- UniformDistribution
- WeibullDistribution
- betafit
- betalike
- binofit
- binolike
- bisafit
- bisalike
- burrfit
- burrlike
- evfit
- evlike
- expfit
- explike
- gamfit
- gamlike
- geofit
- gevfit_lmom
- gevfit
- gevlike
- gpfit
- gplike
- gumbelfit
- gumbellike
- hnfit
- hnlike
- invgfit
- invglike
- logifit
- logilike
- loglfit
- logllike
- lognfit
- lognlike
- nakafit
- nakalike
- nbinfit
- nbinlike
- normfit
- normlike
- poissfit
- poisslike
- raylfit
- rayllike
- ricefit
- ricelike
- tlsfit
- tlslike
- unidfit
- unifit
- wblfit
- wbllike
- betacdf
- betainv
- betapdf
- betarnd
- binocdf
- binoinv
- binopdf
- binornd
- bisacdf
- bisainv
- bisapdf
- bisarnd
- burrcdf
- burrinv
- burrpdf
- burrrnd
- bvncdf
- bvtcdf
- cauchycdf
- cauchyinv
- cauchypdf
- cauchyrnd
- chi2cdf
- chi2inv
- chi2pdf
- chi2rnd
- copulacdf
- copulapdf
- copularnd
- evcdf
- evinv
- evpdf
- evrnd
- expcdf
- expinv
- exppdf
- exprnd
- fcdf
- finv
- fpdf
- frnd
- gamcdf
- gaminv
- gampdf
- gamrnd
- geocdf
- geoinv
- geopdf
- geornd
- gevcdf
- gevinv
- gevpdf
- gevrnd
- gpcdf
- gpinv
- gppdf
- gprnd
- gumbelcdf
- gumbelinv
- gumbelpdf
- gumbelrnd
- hncdf
- hninv
- hnpdf
- hnrnd
- hygecdf
- hygeinv
- hygepdf
- hygernd
- invgcdf
- invginv
- invgpdf
- invgrnd
- iwishpdf
- iwishrnd
- jsucdf
- jsupdf
- laplacecdf
- laplaceinv
- laplacepdf
- laplacernd
- logicdf
- logiinv
- logipdf
- logirnd
- loglcdf
- loglinv
- loglpdf
- loglrnd
- logncdf
- logninv
- lognpdf
- lognrnd
- mnpdf
- mnrnd
- mvncdf
- mvnpdf
- mvnrnd
- mvtcdf
- mvtpdf
- mvtrnd
- mvtcdfqmc
- nakacdf
- nakainv
- nakapdf
- nakarnd
- nbincdf
- nbininv
- nbinpdf
- nbinrnd
- ncfcdf
- ncfinv
- ncfpdf
- ncfrnd
- nctcdf
- nctinv
- nctpdf
- nctrnd
- ncx2cdf
- ncx2inv
- ncx2pdf
- ncx2rnd
- normcdf
- norminv
- normpdf
- normrnd
- plcdf
- plinv
- plpdf
- plrnd
- poisscdf
- poissinv
- poisspdf
- poissrnd
- raylcdf
- raylinv
- raylpdf
- raylrnd
- ricecdf
- riceinv
- ricepdf
- ricernd
- tcdf
- tinv
- tpdf
- trnd
- tlscdf
- tlsinv
- tlspdf
- tlsrnd
- tricdf
- triinv
- tripdf
- trirnd
- unidcdf
- unidinv
- unidpdf
- unidrnd
- unifcdf
- unifinv
- unifpdf
- unifrnd
- vmcdf
- vminv
- vmpdf
- vmrnd
- wblcdf
- wblinv
- wblpdf
- wblrnd
- wienrnd
- wishpdf
- wishrnd
- adtest
- anova
- anova1
- anova2
- anovan
- bartlett_test
- barttest
- binotest
- chi2gof
- chi2test
- correlation_test
- fishertest
- friedman
- hotelling_t2test
- hotelling_t2test2
- kruskalwallis
- kstest
- kstest2
- levene_test
- manova1
- mcnemar_test
- multcompare
- ranksum
- regression_ftest
- regression_ttest
- runstest
- sampsizepwr
- signrank
- signtest
- tiedrank
- ttest
- ttest2
- vartest
- vartest2
- vartestn
- ztest
- ztest2
Class Definition: BinomialDistribution
statistics: BinomialDistribution
Binomial probability distribution object.
A BinomialDistribution object consists of parameters, a model
description, and sample data for a binomial probability distribution.
The binomial distribution is a discrete probability distribution that models the number of successes in a sequence of N independent trials, each with a probability of success p.
There are several ways to create a BinomialDistribution object.
- Fit a distribution to data using the
fitdistfunction. - Create a distribution with fixed parameter values using the
makedistfunction. - Use the constructor
BinomialDistribution (N, p)to create a binomial distribution with fixed parameter values N and p. - Use the static method
BinomialDistribution.fit (x, ntrials, alpha)to fit a distribution to the data in x using the same input arguments as thebinofitfunction.
It is highly recommended to use fitdist and makedist
functions to create probability distribution objects, instead of the class
constructor or the aforementioned static method.
Further information about the binomial distribution can be found at https://en.wikipedia.org/wiki/Binomial_distribution
See also: fitdist, makedist, binocdf, binoinv, binopdf, binornd, binofit, binolike, binostat
Source Code: BinomialDistribution
The BinomialDistribution class contains the following properties:
A positive integer value characterizing the number of trials in the
binomial distribution. You can access the N property using dot
name assignment.
Example: 1
Create a binomial distribution with default parameters
pd = makedist ("Binomial")
pd =
BinomialDistribution
binomial distribution
N = 1
p = 0.5
Query parameter 'N' (number of trials)
pd.N
ans = 1
Set parameter 'N'
pd.N = 10
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.5
Use this to initialize or modify the number of trials in a binomial distribution. The number of trials must be a positive integer.
Example: 2
Create a binomial distribution object by calling its constructor
pd = BinomialDistribution (10, 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
Query parameter 'N'
pd.N
ans = 10
This demonstrates direct construction with specific parameters, useful for defining a binomial distribution with known number of trials.
A scalar value in the range characterizing the probability
of success in each trial of the binomial distribution. You can access
the p property using dot name assignment.
Example: 1
Create a binomial distribution with default parameters
pd = makedist ("Binomial")
pd =
BinomialDistribution
binomial distribution
N = 1
p = 0.5
Query parameter 'p' (probability of success)
pd.p
ans = 0.5000
Set parameter 'p'
pd.p = 0.4
pd =
BinomialDistribution
binomial distribution
N = 1
p = 0.4
Use this to initialize or modify the probability of success in each trial. The probability must be between 0 and 1.
Example: 2
Create a binomial distribution object by calling its constructor
pd = BinomialDistribution (10, 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
Query parameter 'p'
pd.p
ans = 0.3000
This shows how to set the success probability directly via the constructor, ideal for modeling specific success rates.
A character vector specifying the name of the probability distribution object. This property is read-only.
A scalar integer value specifying the number of parameters characterizing the probability distribution. This property is read-only.
A cell array of character vectors with each element containing the name of a distribution parameter. This property is read-only.
A cell array of character vectors with each element containing a short description of a distribution parameter. This property is read-only.
A numeric vector containing the values of the distribution
parameters. This property is read-only. You can change the distribution
parameters by assigning new values to the N and p
properties.
A numeric matrix containing the variance-covariance of the parameter estimates. Diagonal elements contain the variance of each estimated parameter and non-diagonal elements contain the covariance between the parameter estimates. The covariance matrix is only meaningful when the distribution was fitted to data. If the distribution object was created with fixed parameters, or a parameter of a fitted distribution is modified, then all elements of the variance-covariance are zero. This property is read-only.
A logical vector specifying which parameters are fixed and
which are estimated. true values correspond to fixed parameters,
false values correspond to parameter estimates. This property is
read-only.
A numeric vector specifying the truncation interval for the
probability distribution. First element contains the lower boundary,
second element contains the upper boundary. This property is read-only.
You can only truncate a probability distribution with the
truncate method.
A logical scalar value specifying whether a probability distribution is truncated or not. This property is read-only.
A scalar structure containing the following fields:
-
data: a numeric vector containing the data used for distribution fitting. -
cens: an empty array, sinceBinomialDistributiondoes not allow censoring. -
frequency: a numeric vector of non-negative integer values containing the frequency information corresponding to the elements of the data used for distribution fitting. If no frequency vector was used for distribution fitting, then this field defaults to an empty array.
The BinomialDistribution class offers the following public methods:
BinomialDistribution: p = cdf (pd, x)
BinomialDistribution: p = cdf (pd, x,
'upper')
p = cdf (pd, x) computes the CDF of the
probability distribution object, pd, evaluated at the values in
x.
p = cdf (…, returns the complement of
the CDF of the probability distribution object, pd, evaluated at
the values in x.
'upper')
Example: 1
Plot various CDFs from the Binomial distribution
x = 0:10;
pd1 = makedist ("Binomial", "N", 10, "p", 0.2);
pd2 = makedist ("Binomial", "N", 10, "p", 0.5);
pd3 = makedist ("Binomial", "N", 10, "p", 0.8);
p1 = cdf (pd1, x);
p2 = cdf (pd2, x);
p3 = cdf (pd3, x);
plot (x, p1, "*b", x, p2, "*g", x, p3, "*r")
grid on
legend ({"N = 10, p = 0.2", "N = 10, p = 0.5", "N = 10, p = 0.8"}, ...
"location", "southeast")
title ("Binomial CDF")
xlabel ("Number of successes")
ylabel ("Cumulative probability")
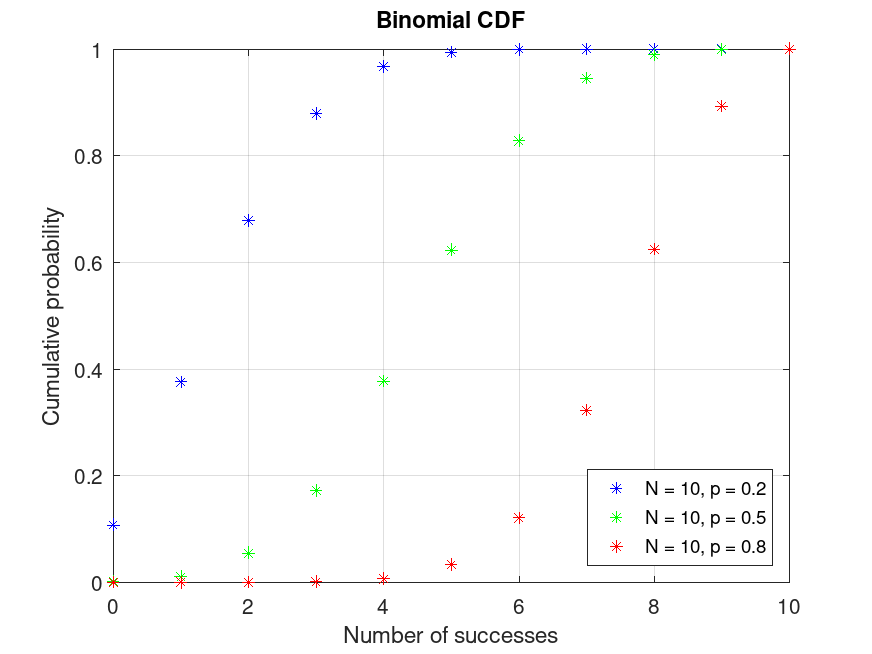
Use this to compute and visualize the cumulative distribution function for different binomial distributions, showing how probability accumulates.
BinomialDistribution: x = icdf (pd, p)
x = icdf (pd, p) computes the quantile (the
inverse of the CDF) of the probability distribution object, pd,
evaluated at the values in p.
Example: 1
Plot various iCDFs from the Binomial distribution
p = 0.001:0.001:0.999;
pd1 = makedist ("Binomial", "N", 10, "p", 0.2);
pd2 = makedist ("Binomial", "N", 10, "p", 0.5);
pd3 = makedist ("Binomial", "N", 10, "p", 0.8);
x1 = icdf (pd1, p);
x2 = icdf (pd2, p);
x3 = icdf (pd3, p);
plot (p, x1, ".b", p, x2, ".g", p, x3, ".r")
grid on
legend ({"N = 10, p = 0.2", "N = 10, p = 0.5", "N = 10, p = 0.8"}, ...
"location", "northwest")
title ("Binomial iCDF")
xlabel ("Probability")
ylabel ("Number of successes")
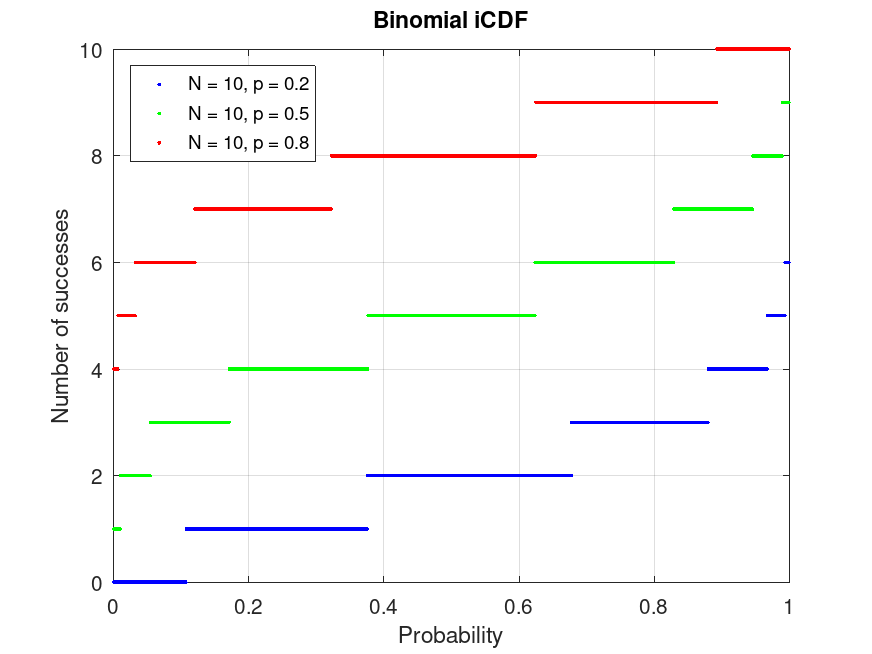
This demonstrates the inverse CDF (quantiles) for binomial distributions, useful for finding the number of successes corresponding to given probabilities.
BinomialDistribution: r = iqr (pd)
r = iqr (pd) computes the interquartile range of the
probability distribution object, pd.
Example: 1
Compute the interquartile range for a Binomial distribution
pd = makedist ("Binomial", "N", 20, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 20
p = 0.3
iqr_value = iqr (pd)
iqr_value = 2
Use this to calculate the interquartile range, which measures the spread of the middle 50% of the distribution.
BinomialDistribution: m = mean (pd)
m = mean (pd) computes the mean of the probability
distribution object, pd.
Example: 1
Compute the mean for different Binomial distributions
pd1 = makedist ("Binomial", "N", 10, "p", 0.2);
pd2 = makedist ("Binomial", "N", 10, "p", 0.5);
mean1 = mean (pd1)
mean1 = 2
mean2 = mean (pd2)
mean2 = 5
This shows how to compute the expected number of successes for binomial distributions with different parameters.
BinomialDistribution: m = median (pd)
m = median (pd) computes the median of the probability
distribution object, pd.
Example: 1
Compute the median for different Binomial distributions
pd1 = makedist ("Binomial", "N", 10, "p", 0.2);
pd2 = makedist ("Binomial", "N", 10, "p", 0.5);
median1 = median (pd1)
median1 = 2
median2 = median (pd2)
median2 = 5
Use this to find the median number of successes, which splits the distribution into two equal probability halves.
BinomialDistribution: nlogL = negloglik (pd)
nlogL = negloglik (pd) computes the negative
loglikelihood
of the probability distribution object, pd.
Example: 1
Compute the negative loglikelihood for a fitted Binomial distribution
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
data = random (pd, 100, 1);
pd_fitted = fitdist (data, "Binomial", "ntrials", 10)
pd_fitted =
BinomialDistribution
binomial distribution
N = 10
p = 0.317 [0.288235, 0.346847]
nlogL = negloglik (pd_fitted)
nlogL = -181.52
This is useful for assessing the fit of a binomial distribution to data, lower values indicate a better fit.
BinomialDistribution: ci = paramci (pd)
BinomialDistribution: ci = paramci (pd, Name, Value)
ci = paramci (pd) computes the lower and upper
boundaries of the 95% confidence interval for each parameter of the
probability distribution object, pd.
ci = paramci (pd, Name, Value) computes
the
confidence intervals with additional options specified by
Name-Value pair arguments listed below.
| Name | Value | |
|---|---|---|
'Alpha' | A scalar value in the range specifying the significance level for the confidence interval. The default value 0.05 corresponds to a 95% confidence interval. | |
'Parameter' | A character vector or a cell array of
character vectors specifying the parameter names for which to compute
confidence intervals. By default, paramci computes confidence
intervals for all distribution parameters. |
paramci is meaningful only when pd is fitted to data,
otherwise an empty array, [], is returned.
Example: 1
Compute confidence intervals for parameters of a fitted Binomial distribution
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
data = random (pd, 1000, 1);
pd_fitted = fitdist (data, "Binomial", "ntrials", 10)
pd_fitted =
BinomialDistribution
binomial distribution
N = 10
p = 0.3027 [0.293704, 0.311811]
ci = paramci (pd_fitted, "Alpha", 0.05)
ci = 0.2937 0.3118
Use this to obtain confidence intervals for the estimated parameters, providing a range of plausible values for p given the data.
BinomialDistribution: y = pdf (pd, x)
y = pdf (pd, x) computes the PDF of the
probability distribution object, pd, evaluated at the values in
x.
Example: 1
Plot various PDFs from the Binomial distribution
x = 0:10;
pd1 = makedist ("Binomial", "N", 10, "p", 0.2);
pd2 = makedist ("Binomial", "N", 10, "p", 0.5);
pd3 = makedist ("Binomial", "N", 10, "p", 0.8);
y1 = pdf (pd1, x);
y2 = pdf (pd2, x);
y3 = pdf (pd3, x);
plot (x, y1, "*b", x, y2, "*g", x, y3, "*r")
grid on
legend ({"N = 10, p = 0.2", "N = 10, p = 0.5", "N = 10, p = 0.8"}, ...
"location", "north")
title ("Binomial PDF")
xlabel ("Number of successes")
ylabel ("Probability")
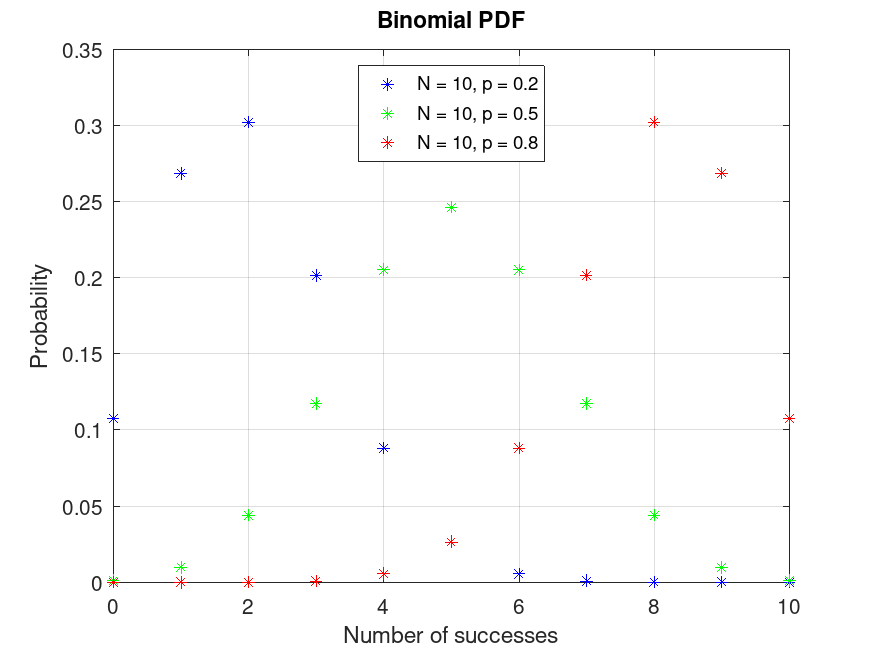
This visualizes the probability mass function for binomial distributions, showing the likelihood of different numbers of successes.
BinomialDistribution: plot (pd)
BinomialDistribution: plot (pd, Name, Value)
BinomialDistribution: h = plot (…)
plot (pd) plots a probability density function (PDF) of the
probability distribution object pd. If pd contains data,
which have been fitted by fitdist, the PDF is superimposed over a
histogram of the data.
plot (pd, Name, Value) specifies additional
options with the Name-Value pair arguments listed below.
| Name | Value | |
|---|---|---|
'PlotType' | A character vector specifying the plot
type. 'pdf' plots the probability density function (PDF). When
pd is fit to data, the PDF is superimposed on a histogram of the
data. 'cdf' plots the cumulative density function (CDF). When
pd is fit to data, the CDF is superimposed over an empirical CDF.
'probability' plots a probability plot using a CDF of the data
and a CDF of the fitted probability distribution. This option is
available only when pd is fitted to data. | |
'Discrete' | A logical scalar to specify whether to
plot the PDF or CDF of a discrete distribution object as a line plot or a
stem plot, by specifying false or true, respectively. By
default, it is true for discrete distributions and false
for continuous distributions. When pd is a continuous distribution
object, option is ignored. | |
'Parent' | An axes graphics object for plot. If
not specified, the plot function plots into the current axes or
creates a new axes object if one does not exist. |
h = plot (…) returns a graphics handle to the plotted
objects.
Example: 1
Create a Binomial distribution with fixed parameters N = 20 and p = 0.4, and plot its PDF.
pd = makedist ("Binomial", "N", 20, "p", 0.4)
pd =
BinomialDistribution
binomial distribution
N = 20
p = 0.4
plot (pd)
title ("Fixed Binomial distribution with N = 20 and p = 0.4")
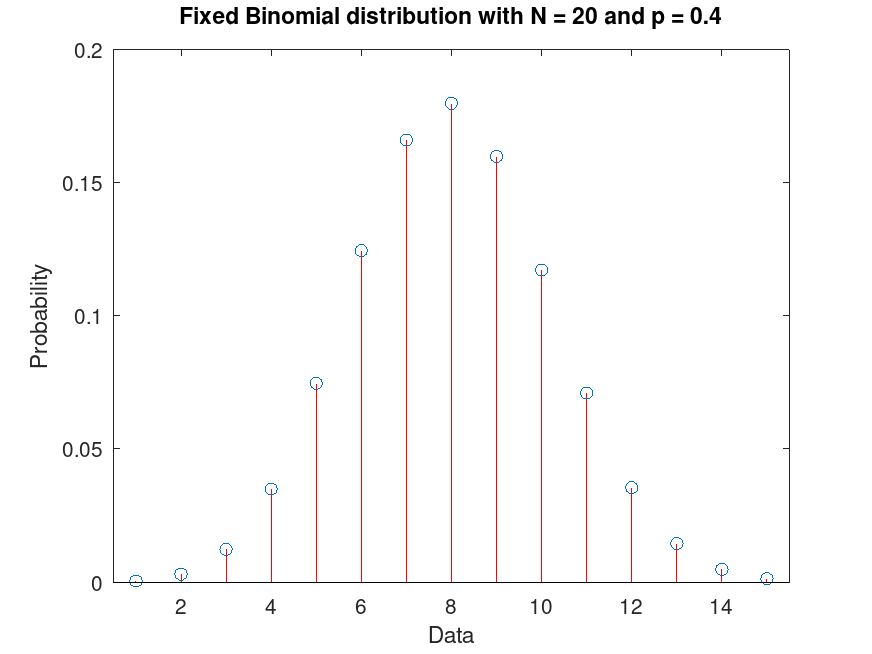
Example: 2
Generate a data set of 100 random samples from a Binomial distribution with parameters N = 10 and p = 0.3. Fit a Binomial distribution to this data and plot its CDF superimposed over an empirical CDF of the data
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
data = random (pd, 100, 1);
pd = fitdist (data, "Binomial", "ntrials", 10)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.317 [0.288235, 0.346847]
plot (pd, "PlotType", "cdf", "Discrete", true)
title (sprintf ("Fitted Binomial distribution with N = %d and p = %0.2f", ...
pd.N, pd.p))
legend ({"empirical CDF", "fitted CDF"}, "location", "southeast")
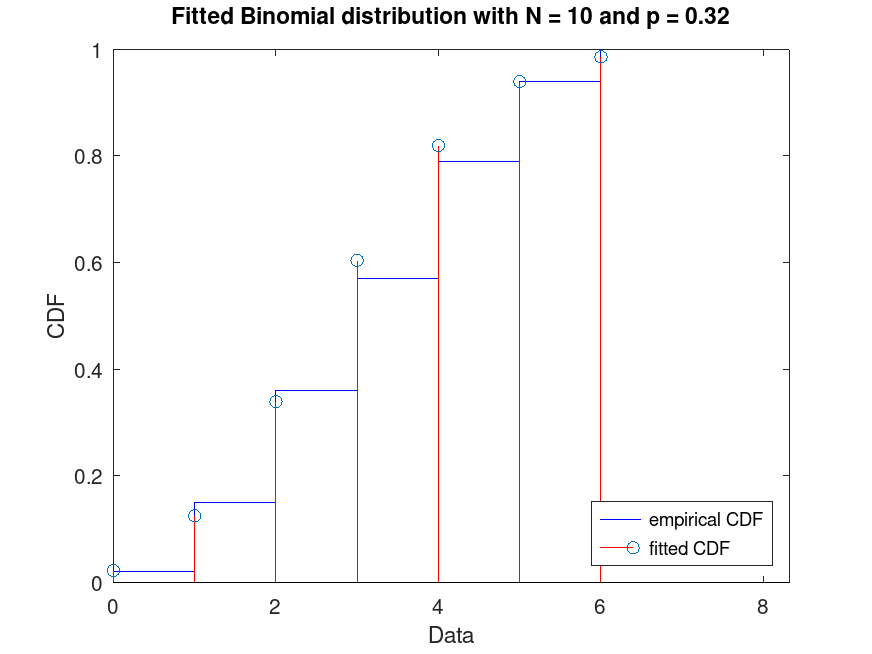
Use this to visualize the fitted CDF compared to the empirical CDF of the data, useful for assessing model fit.
Example: 3
Generate a data set of 200 random samples from a Binomial distribution with parameters N = 10 and p = 0.3. Display a probability plot for the Binomial distribution fit to the data.
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
data = random (pd, 200, 1);
pd = fitdist (data, "Binomial", "ntrials", 10)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.301 [0.280951, 0.321634]
plot (pd, "PlotType", "probability", "Discrete", true)
title (sprintf (["Probability plot of fitted Binomial distribution with " ...
"N = %d and p = %0.2f"], pd.N, pd.p));
legend ({"empirical CDF", "fitted CDF"}, "location", "southeast");
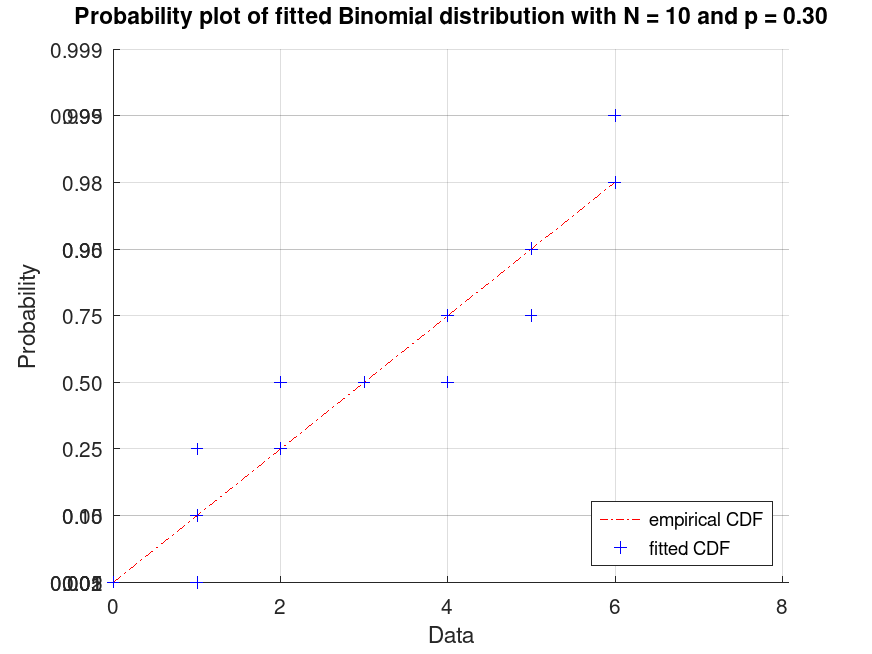
This creates a probability plot to compare the fitted distribution to the data, useful for checking if the binomial model is appropriate.
BinomialDistribution: [nlogL, param] = proflik (pd, pnum)
BinomialDistribution: [nlogL, param] = proflik (pd, pnum,
'Display', display)BinomialDistribution: [nlogL, param] = proflik (pd, pnum, setparam)
BinomialDistribution: [nlogL, param] = proflik (pd, pnum, setparam,
'Display', display)
[nlogL, param] = proflik (pd, pnum)
returns a vector nlogL of negative loglikelihood values and a
vector param of corresponding parameter values for the parameter in
the position indicated by pnum. By default, proflik uses
the lower and upper bounds of the 95% confidence interval and computes
100 equispaced values for the selected parameter. pd must be
fitted to data.
[nlogL, param] = proflik (pd, pnum,
also plots the profile likelihood
against the default range of the selected parameter.
'Display', 'on')
[nlogL, param] = proflik (pd, pnum,
setparam) defines a user-defined range of the selected parameter.
[nlogL, param] = proflik (pd, pnum,
setparam, also plots the profile
likelihood against the user-defined range of the selected parameter.
'Display', 'on')
For the binomial distribution, pnum = 1 selects the
parameter N and pnum = 2 selects the parameter
p.
When opted to display the profile likelihood plot, proflik also
plots the baseline loglikelihood computed at the lower bound of the 95%
confidence interval and estimated maximum likelihood. The latter might
not be observable if it is outside of the used-defined range of parameter
values.
Example: 1
Compute and plot the profile likelihood for the probability parameter of a fitted Binomial distribution
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
data = random (pd, 1000, 1);
pd_fitted = fitdist (data, "Binomial", "ntrials", 10)
pd_fitted =
BinomialDistribution
binomial distribution
N = 10
p = 0.3027 [0.293704, 0.311811]
[nlogL, param] = proflik (pd_fitted, 2, "Display", "on");
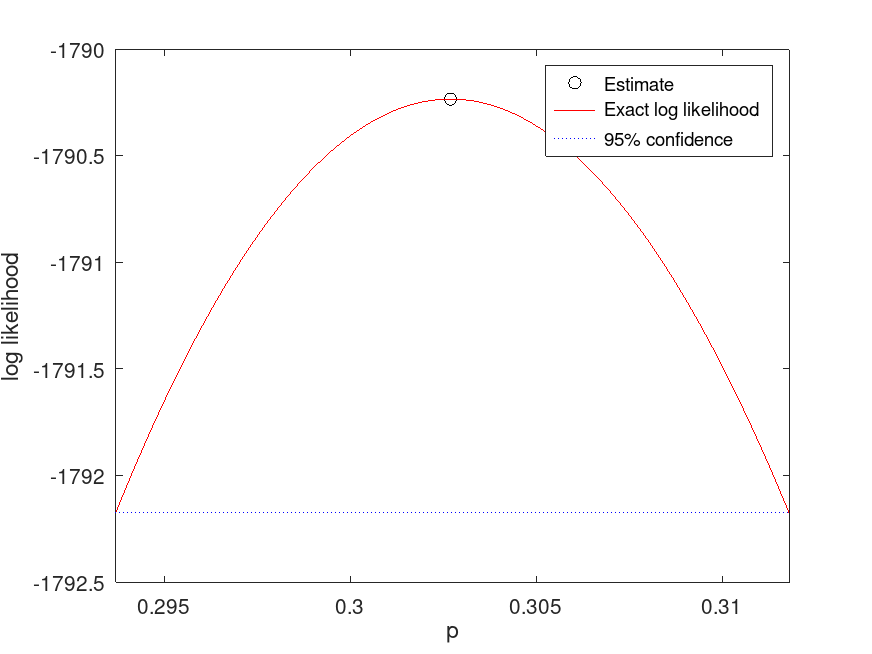
Use this to analyze the profile likelihood of the success probability (p), helping to understand the uncertainty in parameter estimates.
BinomialDistribution: r = random (pd)
BinomialDistribution: r = random (pd, rows)
BinomialDistribution: r = random (pd, rows, cols, …)
BinomialDistribution: r = random (pd, [sz])
r = random (pd) returns a random number from the
distribution object pd.
When called with a single size argument, binornd returns a square
matrix with the dimension specified. When called with more than one
scalar argument, the first two arguments are taken as the number of rows
and columns and any further arguments specify additional matrix
dimensions. The size may also be specified with a row vector of
dimensions, sz.
Example: 1
Generate random samples from a Binomial distribution
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
rand ("seed", 22);
samples = random (pd, 100, 1);
hist (samples, 0:10)
title ("Histogram of 100 random samples from Binomial(N=10, p=0.3)")
xlabel ("Number of successes")
ylabel ("Frequency")
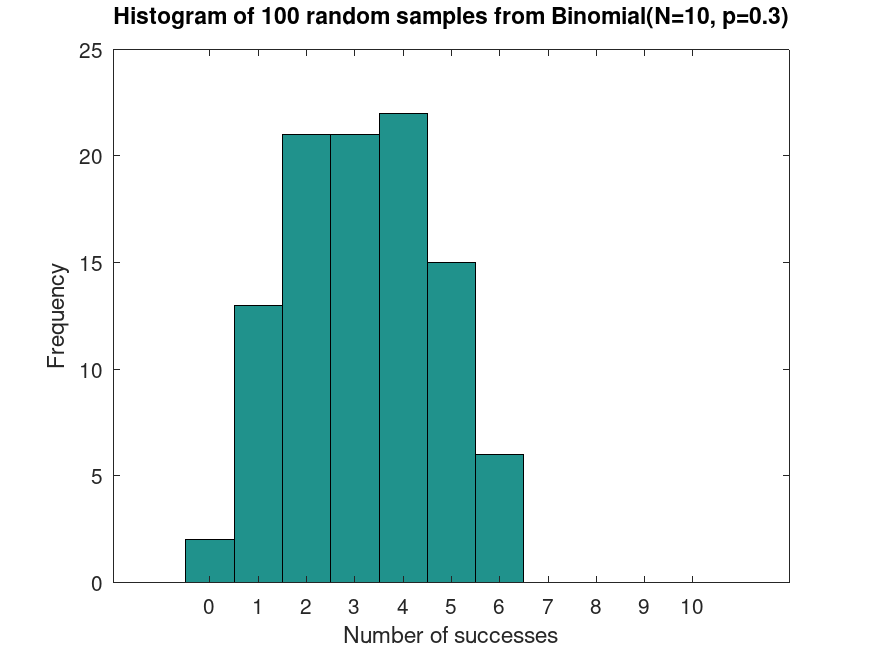
This generates random samples from a binomial distribution, useful for simulating experiments with a fixed number of trials and success probability.
BinomialDistribution: s = std (pd)
s = std (pd) computes the standard deviation of the
probability distribution object, pd.
Example: 1
Compute the standard deviation for a Binomial distribution
pd = makedist ("Binomial", "N", 20, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 20
p = 0.3
std_value = std (pd)
std_value = 2.0494
Use this to calculate the standard deviation, which measures the variability in the number of successes.
BinomialDistribution: t = truncate (pd, lower, upper)
t = truncate (pd, lower, upper) returns a
probability distribution t, which is the probability distribution
pd truncated to the specified interval with lower limit,
lower,
and upper limit, upper. If pd is fitted to data with
fitdist, the returned probability distribution t is not
fitted, does not contain any data or estimated values, and it is as it
has been created with the makedist function, but it includes the
truncation interval.
Example: 1
Plot the PDF of a Binomial distribution, with parameters N = 10 and p = 0.3, truncated at [2, 8] intervals. Generate 10000 random samples from this truncated distribution and superimpose a histogram scaled accordingly
pd = makedist ("Binomial", "N", 10, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
t = truncate (pd, 2, 8)
t =
BinomialDistribution
binomial distribution
N = 10
p = 0.3
Truncated to the interval [2, 8]
rand ("seed", 22);
data = random (t, 10000, 1);
Histogram data for range 2 to 8
edges = 1.5:1:8.5; centers = 2:8; counts = histc (data, edges); counts = counts(1:end-1); # Remove extra edge bin probs = counts / sum(counts); # Normalize to get probabilities
Plot histogram bars
bar (centers, probs, 0.5, "facecolor", [0.6 0.6 1]); hold on;
PMF of the truncated distribution
pmf = pdf (t, centers);
plot (centers, pmf, 'r-', "linewidth", 2);
title ("Binomial distribution (N = 10, p = 0.3) truncated at [2, 8]");
xlabel ("x");
ylabel ("Probability");
legend ("Histogram", "Truncated PMF");
hold off
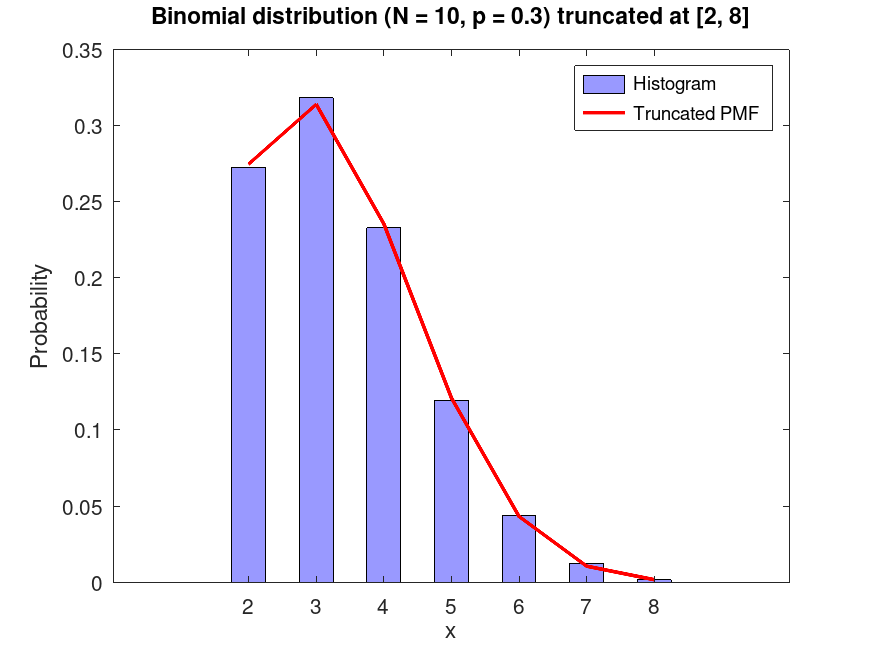
This demonstrates truncating a binomial distribution to a specific range and visualizing the resulting distribution with random samples.
BinomialDistribution: v = var (pd)
v = var (pd) computes the variance of the
probability distribution object, pd.
Example: 1
Compute the variance for a Binomial distribution
pd = makedist ("Binomial", "N", 20, "p", 0.3)
pd =
BinomialDistribution
binomial distribution
N = 20
p = 0.3
var_value = var (pd)
var_value = 4.2000
Use this to calculate the variance, which quantifies the spread of the number of successes in the distribution.